[Note: while the program is also usable in English and has according locale settings, my database is in German, therefore also this documentation is]
KanjiCard ist ein in Java geschriebenes Programm, um Kanji (aus der chinesischen Schrift entlehnte Zeichen der japanischen Schrift) zu lernen. Die Kanji (und Radikale) werden in einer lokalen SQLite-Datenbank gespeichert.
KanjiCard erhebt nicht den Anspruch perfekt zu sein. Ich habe an vielen Stellen den einfachsten/schnellsten Weg beschritten, weil es ein Mittel zum Zweck ist. Schließlich will ich in erster Linie Kanji lernen und kein perfektes Programm schreiben. Gerade der Kanjii-Editor könnte noch etwas Feinschliff gebrauchen und vermutlich werde ich über die Zeit noch ein paar Sachen ändern, aber mein erstes Ziel war, überhaupt einen Editor zu haben, der mir eine schnelle Erstellung
der Strichanimationen erlaubt.
Wichtig war mir, zu jedem Kanji alle sinnvollen Informationen (Radikale usw.), einige Beispielworte und die Strichanimation auf einen Blick sehen zu können. Außerdem sollte der Quizmodus möglichst effektiv sein, also Wiederholungen bereits richtig erkannter Kanji vermeiden usw.
Letzten Endes habe ich KanjiCard programmiert, um genau meine Anforderungen zu erfüllen. Ich habe vorher echte Lernkarten ausprobiert, aber die Schrift war mir zu klein und das Hantieren mit Karten ist keine Lernmethode, die mich sonderlich anspricht. Ich habe auch diverse Apps auf dem Handy ausprobiert, aber die sind fast alle auf Englisch und kaum konfigurierbar. Mir gefiel außerdem der Gedanke, das Quiz in den Autostart einzubinden.
Daß ich die Kanji selber eingeben muß, ist zwar einerseits lästig und es wird noch erhebliche Zeit dauern, bis ich die 2136 Jōyō Kanji (常用漢字) eingegeben haben werde - falls es jemals dazu kommt. Aber für mich persönlich ist das irgendwie auch didaktisch wertvoll.
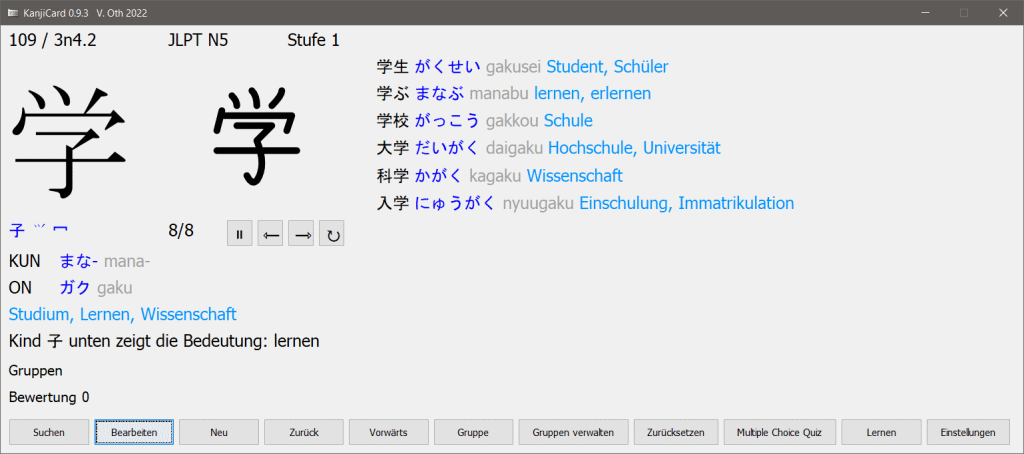
In der Hauptansicht kann man Kanji suchen, bearbeiten, hinzufügen, sie zu Gruppen hinzufügen oder einen der Lernmodi starten.
Die laufende Nummer (ID) und der "Deskriptor" (im obigen Bild 109 und "3n4.2") stammen aus "Japanese Kanji and Kana" bzw. aus dem Japanisch-deutschen Zeichenwörterbuch von Wolfgang Hadamitzky, Mark Spahn und anderen. Die ID wird benutzt, um vorwärts und zurück zu blättern - und weil ich irgendeine Richtlinie gebraucht habe, in welcher Reihenfolge ich die Kanji eingebe. Dadurch gibt es nicht unbedingt eine enge Kopplung an die JLPT-Stufe. Unter den ersten 126 IDs sind zum Beispiel nur 78 von 80 Kanji aus der JLPT-Stufe N5.
Die Suche ist recht rudimentär implementiert. Sie soll nur dazu dienen, Kanji wiederzufinden, um sie zu bearbeiten, aber kein Wörterbuch o.ä. ersetzen.
Man kann die Lesungen und Bedeutungen per Freitextsuche durchsuchen. Zusätzlich kann man die Suche durch die Vorgabe von Radikalen, JLPT-Stufe usw. einschränken.

Ein "[-]" bedeutet dabei immer: keine Einschränkung. Ansonsten werden die zugelassenen Kriterien explizit aufgelistet. Die ausgewählten Kriterien innerhalb einer Kategorie werden in der Regel per "ODER" verknüpft und die verschiedenen Kategorien per "UND". Eine Ausnahme sind die Radikale, denn dort gilt auch für die ausgewählten Radikale eine "UND"-Verknüpfung.
Wenn man das entsprechende Feld einer Kategorie anklickt, öffnet sich ein Fenster mit einer Listenauswahl:
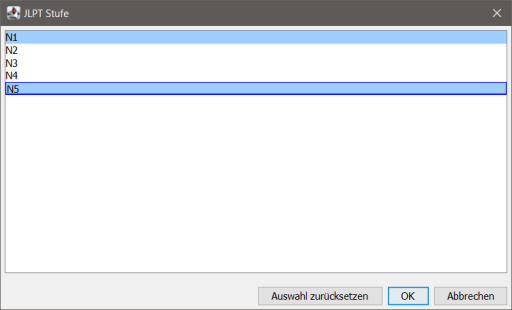
Hier kann man per Mehrfachauswahl (Ctrl+Klick usw.) mehrere Einträge auswählen. Per "Auswahl zurücksetzen" kommt man wieder zu Standardauswahl ("[-]") zurück.
Falls etwas gefunden wurde, öffnen sich ein Fenster mit einer Liste der gefundenen Einträge. Per Doppelklick auf einen der Einträge springt man dorthin:
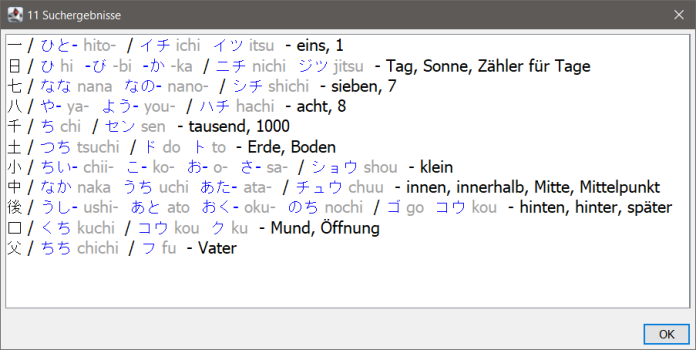
Per "Bearbeiten" (des derzeitigen Eintrages) oder "Neu" (Erstellen eines Eintrags) öffnen sich der Dialog zur Bearbeitung der Einträge.
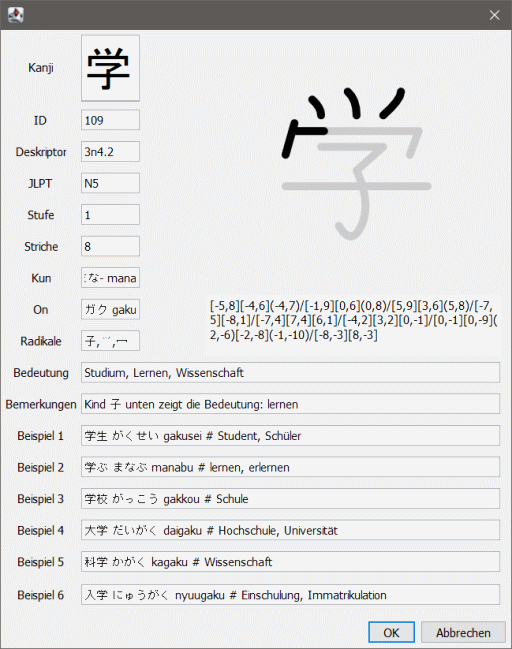
Das Kanji ist das Ordnungskriterium der Datenbank. Pro Kanji kann es nur einen Eintrag geben. Die Werte für ID, Stufe und Striche müssen positive ganze Zahlen größer 0 sein. Aus praktischen Gründen sollte auch die ID eineindeutig sein.
Die Einträge zur Lesung und die Radikale werden mit Kommata getrennt, also zum Beispiel "あざ aza, あざな azana, -な -na". Bei den Lesungen kommen immer erst die Kana, dann die Romaji.
Die Radikale können entweder in der Radikaldatenbank oder in der Kanji-Datenbank gespeichert sein. In diesem Fall werden sie im Hauptfenster als Links angezeigt und wenn man mit dem Maus über den Link fährt, wird die Bedeutung angezeigt.
Bei den Beidpielen kommt zuerst die Schreibweise mit Kanji, dann die Lesung in Kana und dann die in Romaji. Die Übersetzung muß mit einem Lattenkreuz "#" abgetrennt sein.
Rechts oben wird die Strichanimation gezeigt. Wenn man auf diesen Bereich klickt, öffnen sich der eigentliche Kanji-Editor. Darunter ist die Streichfolge als Zeichenkette dargestellt. Die Striche sind per "/" getrennt, die Punkte der Linien stehen jeweils in eckigen Klammern [x,y]. Zwei Punkte ergeben eine einfache Linie, mehrere Punkte ergeben komplexere Strichzüge. Wenn nach einem Punkt ein Wert in runden Klammern steht, dann ist das der Kontrollpunkt für eine quaratische Spline-Interpolation. Das dient zum einfachen Zeichnen gebogener Linien. Man kann auch in diesem Fenster editieren, aber primär ist es für Copy/Paste (Ctrl+C, Ctrl+V) gedacht, um die Strichanimation ähnlicher Kanji vor dem Bearbeiten zu übernehmen.
Der Kanji-Editor ist eine Kernkomponente, weil er die einfache und schnelle Erzeugung von Strichanimationen erlaubt. Der Editor benutzt absichtlich eine recht grobe Rasterung, um die Freiheitsgrade bei der Bearbeitung zu reduzieren und damit zu vereinfachen.
Die Animation wird aus der so vorgegebenen Reihenfolge und Richtung der Striche zur Laufzeit automatisch erzeugt.
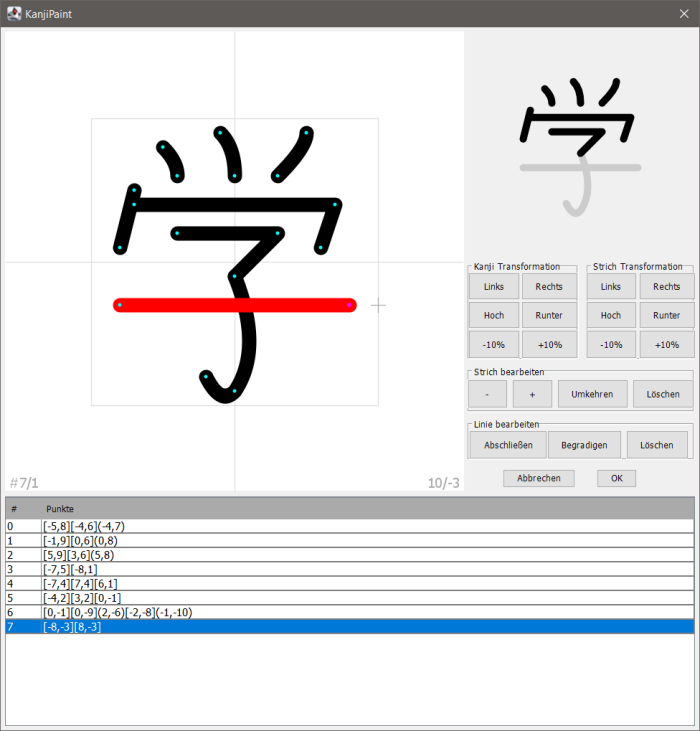
Oben links ist der Zeichenbereich, unten sieht man eine tabellarische Darstellung der Striche und rechts in der Mitte gibt es einige Schaltflächen für Sonderfunktionen.
Mit der linken Maustaste wählt man Punkte aus. Bei gedrückt gehaltener Maustaste verschiebt man Punkte. Ein Klicken außerhalb der Punkte eines Strichs schließt die Bearbeitung des Strichs ab.
Wenn man den Endpunkt einer Linie anklickt (also jeden Punkt eines Strichs mit Ausname des ersten Punkts), dann wird die Linie rot und man kann mit gehdrückter rechter Maustaste den Kontrollpunkt für die quadratische Spline-Interpolation verschieben und so die Linie verbiegen. Ansonsten wird der aktuelle Strich blau hervorgehoben und auch in der Tabelle entsprechend markiert. Man kann auch durch Anklicken einer Zeile in der Tabelle den entsprechenden Strich auswählen.
Links unten um Zeichenfenster werden der (bei Null beginnende interne) Index des Strichs und des Punkts im Strich angezeigt, der gerade aktiv ist. Rechts unten sieht man die aktuelle Koordinate des Cursors (x/y).
Mit den Schaltflächen unter "Transformation" kann man das ganze Kanji oder den aktuellen Strich verschieben oder skalieren.
Unter "Strich bearbeiten" kann man per "+"/"-" die Position des aktuellen Strichs in der Strichfolge ändern. Mit "Umkehren" dreht man die Richtung des Strichs und mit "Löschen" löscht man den Strich.
Unter "Linie bearbeiten" kann man die aktuelle Linie (und damit auch den Stich) abschließen. Den gleichen Effekt hat das Drücken der Eingabetaste oder das Klicken außerhalb vorhandener Punkte. Mit "Begradigen" entfernt man den Kontrollpunkt der quadratischen Spline-Interpolation und mit "Löschen" löscht man den aktuellen Endpunkt der Linie. Wenn es nur noch zwei Punkte gibt, bleibt ein Startpunkt zurück, was für ein Kanji unsinnig wäre, aber während der Bearbeitung OK ist. Wenn man auch den letzen Punkt eines Strichs löscht, dann löscht man automatisch auch den Strich.
Es gibt ein Undo/Redo mit Ctrl+Z und Ctrl+Y. Bei komplexeren Kanji kann es trotzdem Sinn ergeben, während der Bearbeitung immer mal wieder den Status Quo per "OK" zu sichern, damit man zur Not per Abbrechen zu diesem Punkt zurückkehren kann.
Um für das Lernen benutzerdefinierbare Gruppen auswählen zu können, kann man jedem Kanji beliebig vielen Gruppen zuordnen. In der Datenbank wird für jedes Kanji eine einfache Zeichenkette benutzt, um die Gruppen zu speichern, in denen ein Kanji eingeordnet ist. Die Gruppennamen sind dabei links und rechts von Schrägstrichen ("/") eingeschlossen. Das ist insofern wichtig zu wissen, weil dadurch Gruppen nur existieren können, wenn mindestens ein Kanji diese Gruppe
benutzt.
Die Gruppen, zu dem das aktuelle Kanji gehört, werden im Hauptdialog unter "Gruppen" angezeigt. Wenn man auf eine Gruppe klickt, erscheint ein Popup-Menü, mit dem man die Gruppe anzeigen oder das Kanji aus dieser Gruppe löschen kann. Wenn man die Gruppe anzeigt, kann man (wie bei den Suchergebnissen) durch Doppelklick auf jeden Eintrag zu dem entsprechenden Kanji springen.
Zusätzlich gibt es die Schaltfläche "Gruppe", mit dem man die einem Kanji zugeordneten Gruppen anzeigen und bearbeiten kann:
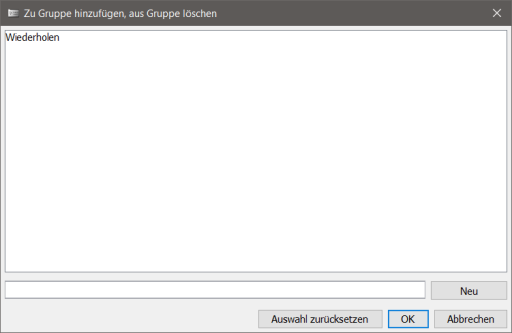
Angezeigt werden alle Gruppen, die es in der Datenbank gibt. Wenn sie selektiert sind, dann sind sie dem aktuellen Kanji zugeordnet, ansonsten andern Einträgen. Hier kann man wie bei der Suche per Mehrfachauswahl (Ctrl+Klick usw.) mehrere Einträge auswählen. Per "Auswahl zurücksetzen" löscht man die Zugehörigkeit zu allen Gruppen. Per "Neu" kann man eine neue Gruppe erzeugen (deren Namen man vorher links davon eingeben muß) und dem Kanji zuordnen.
Achtung: weil Gruppen nicht ohne Kanji existieren können, wird eine per "Neu" erzeugte Gruppe nicht erzeugt, wenn man sie für dieses Kanji wieder abwählt.
Desweiteren gibt es noch die Schaltfläche "Gruppen verwalten". Es öffnen sich ein Fenster mit der Liste aller vorhandenen Gruppen. Man kann hier per Doppelklick die zu einer Gruppe gehörenden Kanji anzeigen (und von dort aus wieder per Doppelklick zum Kanji wechseln). Außerdem kann man per "Auswahl löschen" alle per Mehrfachauswahl selektieren Gruppen aus der Datenbank löschen. Weil die Gruppen ja Kanji zurgeordnet sind, wird jeder einzelne Datenbankeintrag geprüft, ob eine der zu löschenden Gruppen vorhanden ist und dann gelöscht.
Weil einige persönliche Informationen wie Lernerfolge und die Gruppenzuordnungen zusammen mit den allgemeingültigen Einträgen pro Kanji gespeichert werden, kann man mit dieser Option alle persönlichen Informationen aus der Datenbank löschen. Es öffnet sich folgender Dialog:

Mit "Diese Bewertung zurücksetzen" löscht man den Erfolgszähler für das aktuelle Kanji und mit "Alle Bewertungen zurücksetzen" für alle Einträge in der Datenbank. Per "Alle Gruppen löschen" löscht man alle Gruppenzuordnungen aus der Datenbank.
Ist eigentlich hauptsächlich für mich gedacht, bevor ich eine neue Datenbank ins Archiv hochlade bzw. für andere Leute, die meine Gruppen und Bewertungen löschen wollen, falls ich das mal vergesse.
Es gibt zwei Lernmodi. Mit "Lernen" werden Lesungen usw. verdeckt und man kann per "Anzeigen" alle Informationen aufdecken. Anschließend kann man selber entscheiden, ob man das Kanji korrekt erkannt hat oder nicht.
Mit "Quiz" werden jeweils sechs Möglichkeiten zur Auswahl angezeigt und man muß die richtige Antwort anklicken.
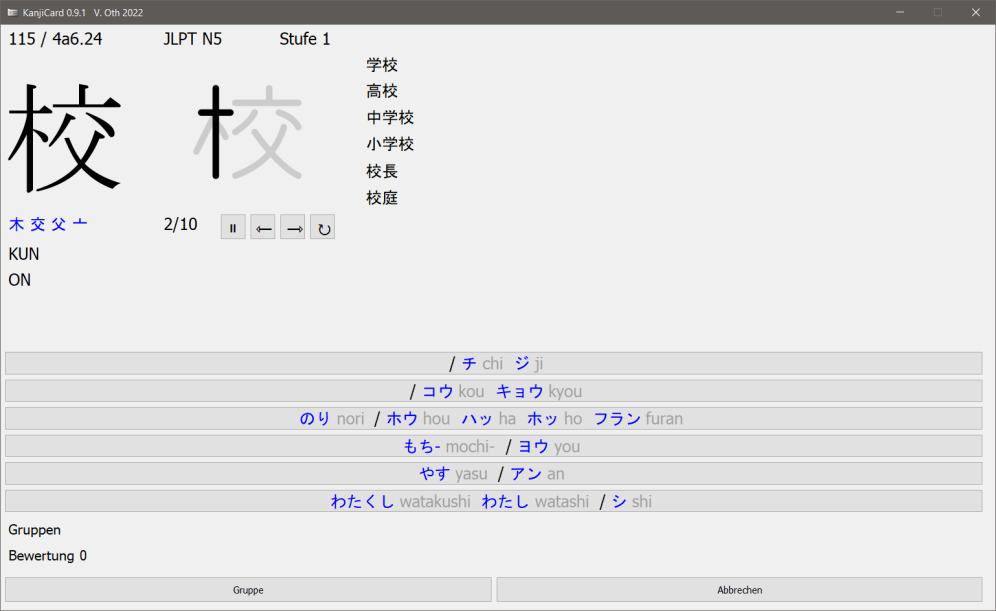
Die Antwort wird dann automatisch als richtig oder falsch bewertet. Um Fortzufahren, muß man irgendwo im Feld mit den Antworten klicken..
Während des Lernens werden alle normalen Schaltflächen bis auf "Gruppe" und "Abbrechen" ausgeblendet. Damit kann man einen Eintrag auch während des Lernens einer Gruppe zuordnen oder das Lernen abbrechen.
Mir war wichtig, daß das Quiz nicht immer wieder die gleichen Einträge benutzt, die ich schon kenne. Deshalb habe ich ein zwei Mechanismen eingebaut, die das verhindern sollen.
In beiden Modi werden richtige Antworten in einer Liste gespeichert und für die nächsten Runden (als richtige Antwort) des laufenden Quiz'/Lernens vermieden. Zusätzlich wird er als "Bewertung" anzeigte Erfolgszählers eines Kanji bei einer richtigen Antwort erhöht und bei einer falschen Antwort erniedrigt. Weil dieser Zähler in der Datenbank gespeichert wird, sollten nach einiger Zeit die gut erkannten Kanji einen höhere Erfolgszähler haben also solchem die man
oft nicht korrekt erkannt hat. Das wird dazu benutzt, um bei Lernen bzw. im Quiz Einträge zu bevorzugen, die man besonders oft nicht richtig erkannt hat. Neue Einträge starten mit dem Wert 0, aber der Zähler kann natürlich negativ werden.
Ich hatte mir ursprünglich noch höhere Ziele gesetzt (absichtliche ähnlich aussehende Kanji zur Auswahl anbieten) und vielleicht mache ich das noch, aber für den Augenblick funktioniert der gewählte Ansatz schon recht gut.
Per "Einstellungen" öffnen sicht der entsprechende Dialog. Abgesehen von der Sprachauswahl der Benutzeroberfläche dienen Einstellungen hauptsächlich der Konfiguration des Quiz' bzw. Lernmodus.
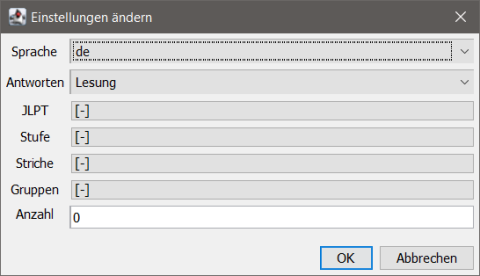
Bei "Antworten" kann man auswählen, ob im Quiz nur die Lesungen, nur die Bedeutungen oder beide in den zur Auswahl stehenden Antworten benutzt werden. Für den Lernmodus hat diese Auswahl keine Bedeutung.
"JLPT", "Stufe", "Striche" und "Gruppen" dienen wie bei der Suche der Einschränkung der im Quiz bzw. Lernmodus zu verwendenden Einträge. Mit "Anzahl" kann man eine feste Anzahl von Runden festlegen, nach denen das Quiz/Lernen automatisch endet. Eine Null bedeutet keine Beschränkung. Das Quiz/Lernen wird dann fortgesetzt, solange es noch einen falsch beantworteten Eintrag in der Datenbank gibt (der den Filterkriterien entspricht) oder bis der Anwender
das Quiz/Lernen abbricht.
Die Einstellungen werden (zusammen mit der Fensterposition) in einer Datei namens "KanjiCard.ini" im gleichen Verzeichnis wie JAR und Datenbank gespeichert.
Nachdem KanjiCard ein Java-Programm ist, braucht es eine Java Laufzeitumgebung. Wegen der zunehmend restrikteren Lizenzbedingungen der Oracle JRE/JDK rate ich zur OpenJDK. Ich habe aus Gründen der Abwärtskompatibilität nur Features benutzt, die schon in der recht alten JRE/JDK 8 zur Verfügung gestanden haben, neuere Versionen sollte aber kein Problem sein. Java ist (von Bugs abgesehen) sehr um Abwärtskompatibilität bemüht. Meine JARs von 2005 laufen auch noch unter einer JDK 11 problemlos.
Unter manchen Konstellationen von Betriebssystem und Laufzeitumgebung kann es dazu kommen, daß die Java-Laufzeitumgebung einen falschen Zeichensatz für die Kanji auswählt. In meinem Fall wurde der chinesische Zeichensatz "MingLiU" statt eines japanischen Zeichensatzes (Ms Gothic or MS Mincho) ausgewählt. Die Unterschiede waren subtil, aber dennoch irrtierend.
Leider gibt es derzeit keine Möglichkeit, diese Auswahl der Laufzeitumgebung per Property usw. zur Laufzeit aus einem Programm heraus zu ändern. Ich habe deshalb auf meinen Hauptrechner folgenden Workaround anwenden müssen:
Die Datei "fontconfig.properties.src" im "lib"-Verzeichnis der verwendeten Java-Laufzeitumgebung finden. Eine Kopie der Datei erzeugen und in "fontconfig.properties" (ohne ".src") umbenennen. Dann "japanese" in der Fallback-Sequenz ganz nach vorne schieben:
sequence.fallback=symbols,\
japanese,korean,chinese-ms950-extb,chinese-ms936-extb,\
chinese-ms950,chinese-hkscs,chinese-ms936,chinese-gb18030,\
georgian,devanagari,bengali,gujarati,gurmukhi,kannada,\
malayalam,oriya,sinhala,tamil,telugu,thai,khmer,mongolian,\
myanmar
Zusätzlich fehlen in den für japanische Schrift benutzten Fonts "MS Gothic" und "MS Mincho" (die man gegebenenfalls ohnehin nachinstallieren muß) einige Radikale.
Im Zweifelsfall habe ich jetzt unter Windows 11 alle "x.y.japanese"-Einträge in "fontconfig.properties" auf "Meiryo UI" geändert. Damit scheinen alle Radikale richtig angezeigt zu werden. Auch hier kann es sein, daß man die Schrift als Teil des japanischen Sprachpakets oder unter "System->Optionale Features" nachinstallieren muß.
Die SqLite Datenbank wird in der Datei "KanjiCard.db" gespeichert, die im gleichen Pfad wie die JAR-Datei liegen muß. Sie enthält zwei Tabellen: "kanjiTable" enthält alle Datenbankeinträge für die Kanji. Zudem gibt es noch eine Tabelle für die Radikale namens "radicalTable". Diese Tabelle kann aus dem Programm heraus nicht bearbeitet werden, weil ich sie als fix betrachte und den Aufwand eines zusätzlichen Editors bislang gescheut habe. Wenn man diese Radikaldatenbank für Korrekturen, Ergänzungen, Übersetzungen usw. ändern will, ist man auf einen externen Editor angewiesen. Ich habe dazu den frei verfügbaren DB Browser for SQLite benutzt, den ich nur empfehlen kann.
Alle in der Benutzeroberfläche benutzen Zeichenketten (die nicht aus der Datenbank kommen) werden über die Datei "KanjiCard Locale.ini" definiert. Wie die Datenbank muß sie im Programmverzeichnis liegen. Es ist eine einfache INI-Datei, wobei jede Sprache mit einem Eintrag in eckigen Klammern beginnt. Per Default gibt es "[ENG]" für Englisch und "DE" für Deutsch. Danach folgen die Einträge in der Form "READING = Lesung" wobei links
immer das Symbol und rechts die zu verwendende Zeichenkette steht.
Man könnte also zum Beispiel einfach eine niederländische Übersetzung ergänzen, indem man eine Sektion "[NL]" erzeugt und für alle Symbole eine entsprechende Übersetzung angibt. Natürlich wäre die Anpassung der Datenbanken die größere Aufgabe.
java -jar KanjiCard.jarUnter Windows sollte man allerdings "javaw" verwenden, weil sonst immer eine Konsole aufgeht (und offen bleibt). Um also unter Windows im Quizmodus zu starten, würde die volle Kommandozeile so aussehen:
javaw -jar KanjiCard.jar /Q
Um das im Programm verwendete Icon auch ein Windows benutzen zu können, liegt eine "*.ICO"-Datei im Archiv. Man man dann der Desktopverknüpfung einfach ein neues Symbol zuordnen.
Eine lauffähige Version mit Datenbank kann man hier herunterladen:
https://bitbucket.org/fade0ff/kanjicard/downloads/
Einfach das 7z-Archiv in einen beliebigen Ordner entpacken und die JAR-Datei von dort ausführen.
Alle notwendigen Dateien liegen im BitBucket -Archiv
https://bitbucket.org/fade0ff/KanjiCard
Zum Übersetzen des Projekts muß man die JAR-Datei der SQLite-JDBC-Bibliothek herunterladen, in den Quellcodepfad kopieren und ins Projekt einbinden.
In Eclipse geht das mit Project->Properties->Java Build Path->Libraries->Add external JARs.
Um während der Entwicklung auf die Lokalisierung und die Datenbank zugreifen zu können, müssen die entsprechenden Dateien in den Pfad der Binärdateien (üblicherweise "bin") kopiert werden.
Man sollte sie aber nicht dem Projekt hinzufügen, sonst landen sie am Ende im JAR.
KanjiCard ist ein nichtkommerzielles Projekt, daß ich in meiner Freizeit entwickelt habe. Benutzung auf eigene Verantwortung.
Alle von mir erstellten Teile sind unter der Creative
Commons CC-BY Lizenz veröffentlicht.

Kurz gesagt bedeutet das, daß man das Programm, den Quellcode usw. teilen, verändern und benutzen kann. Auch eine kommerzielle Nutzung ist möglich.
Man muß lediglich mich als Quelle angeben, die Änderungen erläutern und davon absehen, den übernommenen Quellcode unter restriktivere Lizenzen zu stellen.
Für Details verweise ich auch die Lizenbedinungen der CC BY.
Nicht von mir stammt die Bibliothek zum Zugriff auf SQLite per Java:
https://github.com/xerial/sqlite-jdbc
Sie ist unter der Apache Lizenz 2.0 veröffentlicht.